8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
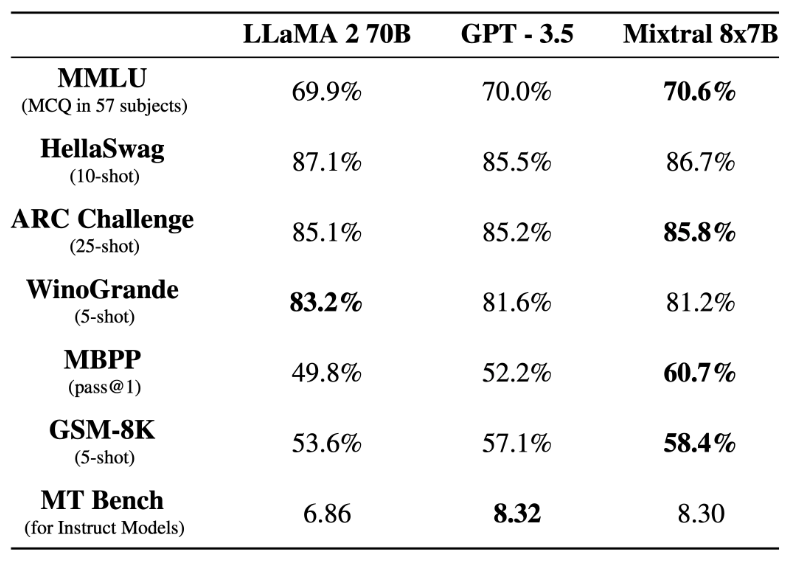
8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。
来自主题: AI技术研报
6654 点击 2024-01-01 11:08
 搜索
搜索
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。
「高端」的开源,往往采用最朴素的发布方式。昨天,Mistral AI 在 X 平台甩出一条磁力链接,宣布了新的开源动作。